5 分钟让你的服务接入 AI——用 API Auto MCP Server 实现大模型与后端系统的无缝对话
想象一下,面对一个拥有成百上千接口的后端服务,通过它,不仅可以获取海量数据进行数据分析,还可以筛选查找特定用户帮助解决问题,或者是在回归环境通过调用接口创建特定的测试用户。
但问题在于,人类去一个个接口找出来,一个个编写参数去调用是非常繁琐,每个接口通常需要依托于特定的可视化页面,比如各种后台系统。但是,即便如此,一个一个页面去操作,一个一个功能去调用依然是效率极低的。
就不能直接让 AI 去干这些活吗?让它直接帮我查找分析数据、调用各种接口创建测试账户,让它直接调用接口生成对应的数据表格,直接和后台页面说再见。
当然可以!先看看这个效果: 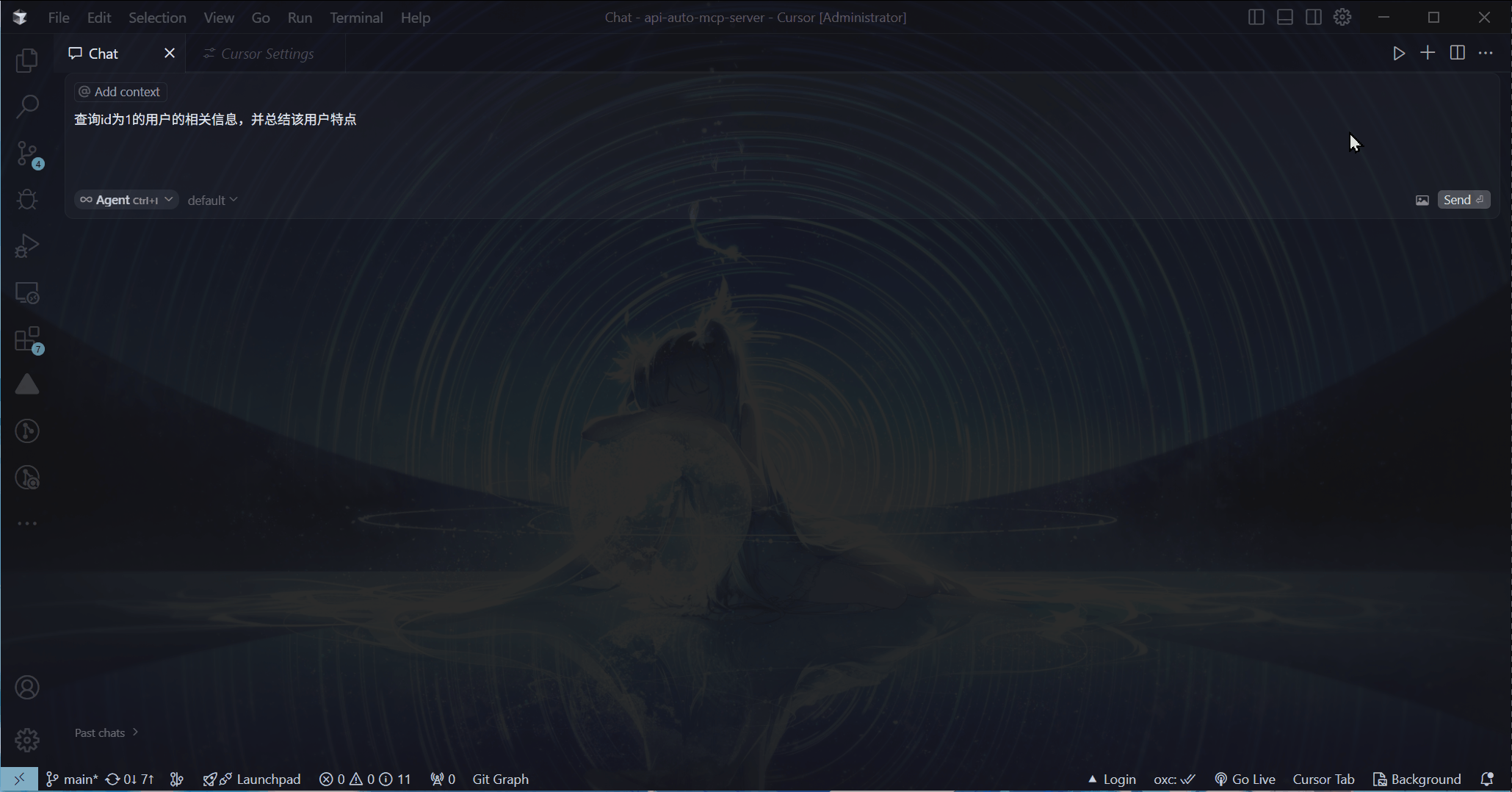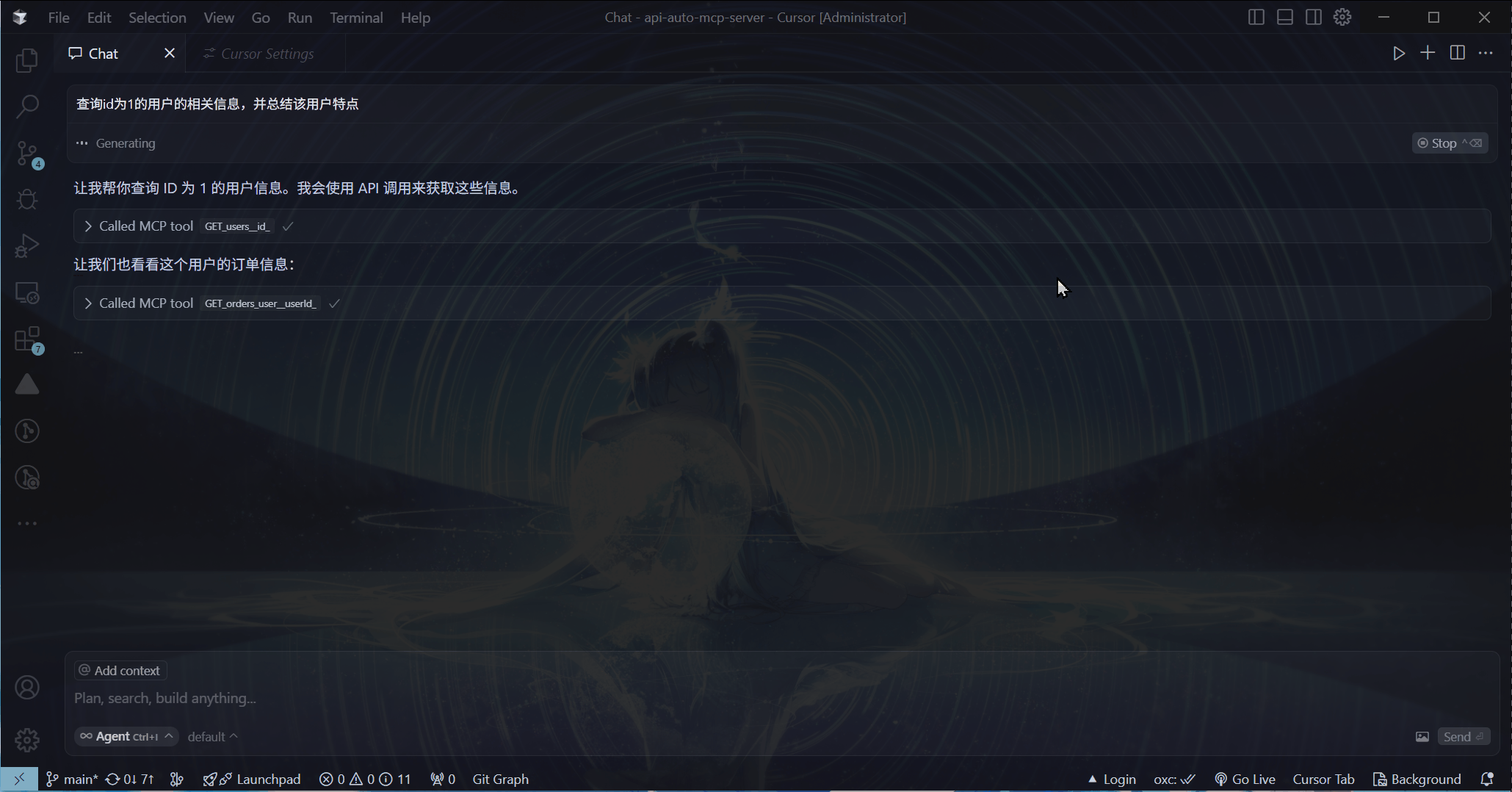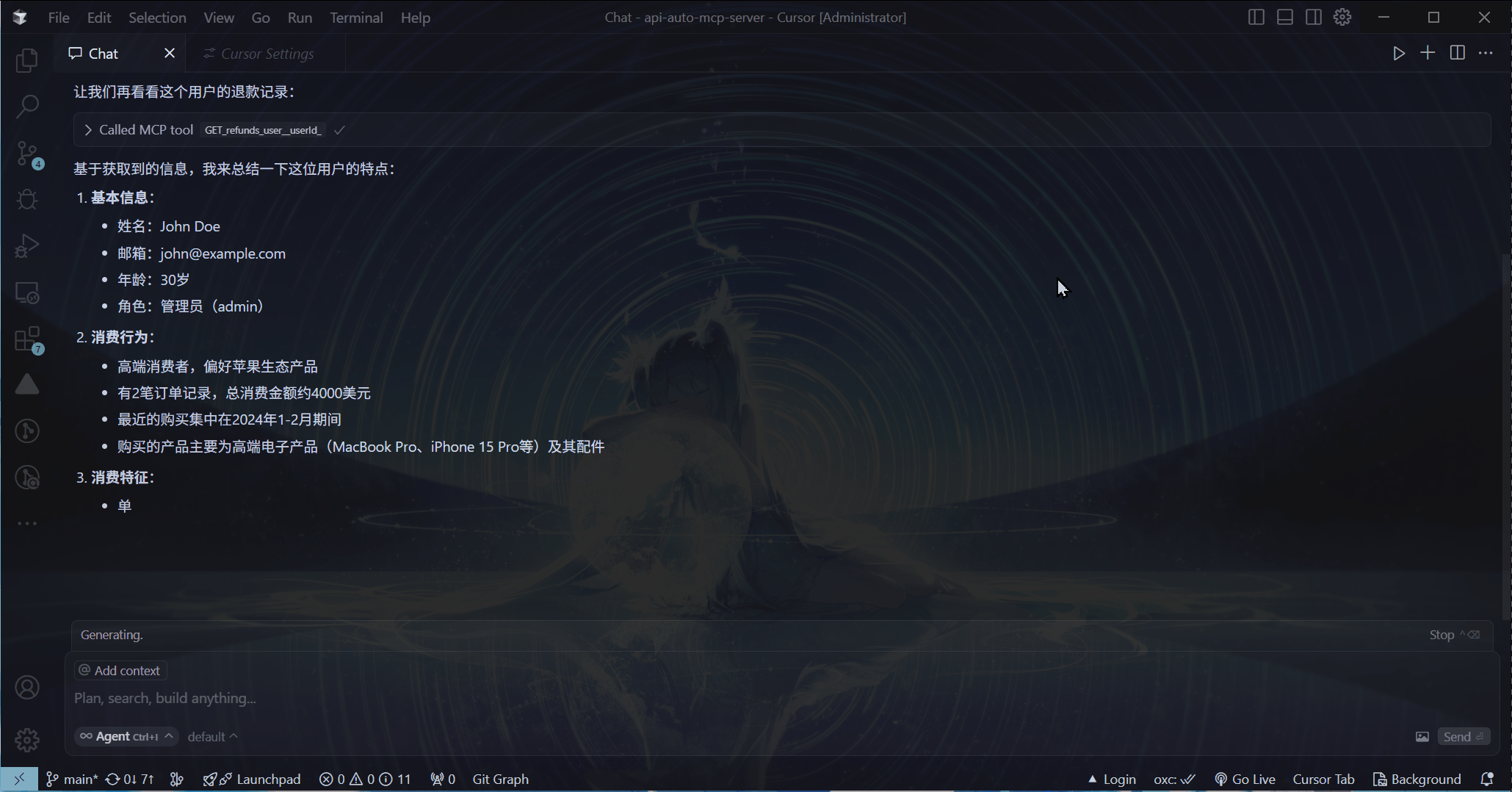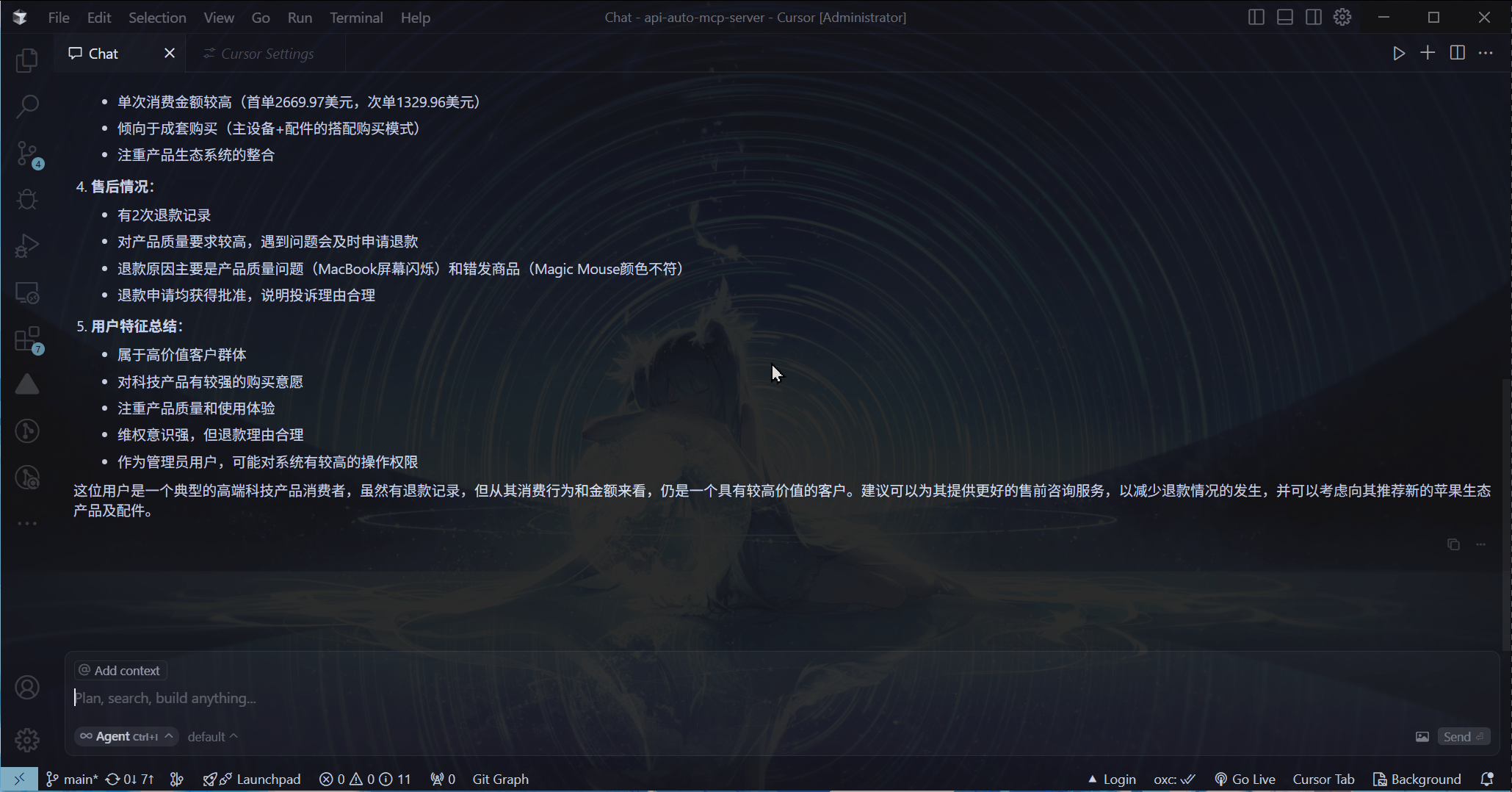
直接使用Cursor内置的AI功能进行提问
这里我向AI提出问题, AI 就根据问题自动调取对应的接口获取信息,然后将这些获取到的信息进行汇总呈现给我。
而要实现这一切,只需要将你的后端服务配置上 API Auto MCP Server 即可,接下来我将手把手教你如何将这一工具用于自己的后端系统。
快速上手
我准备了一个示例项目—— API Auto MCP Server Demo ,使用该项目可以快速体验和熟悉这一MCP Server的使用。
环境准备
- 运行环境:
Node.js>= 22; - 带有AI功能的集成开发环境: Cursor >= 0.46.8 或 VScode >= 1.99.3(需要启用Github Copilot插件)
安装依赖
在项目根目录下,执行以下命令安装依赖:
npm install启动服务
使用 VScode 或 Cursor 等IDE打开该项目后,按F5运行(推荐)。
或在根目录下执行以下命令启动服务:
npm run dev访问服务
等待启动完成后,访问http://localhost:3000/api-docs,如果可以看到接口文档就说明项目已经成功启动。
启动MCP服务器
Cursor
如果是使用Cursor打开该项目,根据下图示意:
- 打开
Cursor Settings; - 进入
MCP选项; - 找到名为
api-auto的MCP服务器,将其设置为开启状态。
当开启成功后,界面中会出现各种可供调用的 Tools,此时便完成了 MCP 服务器的激活。 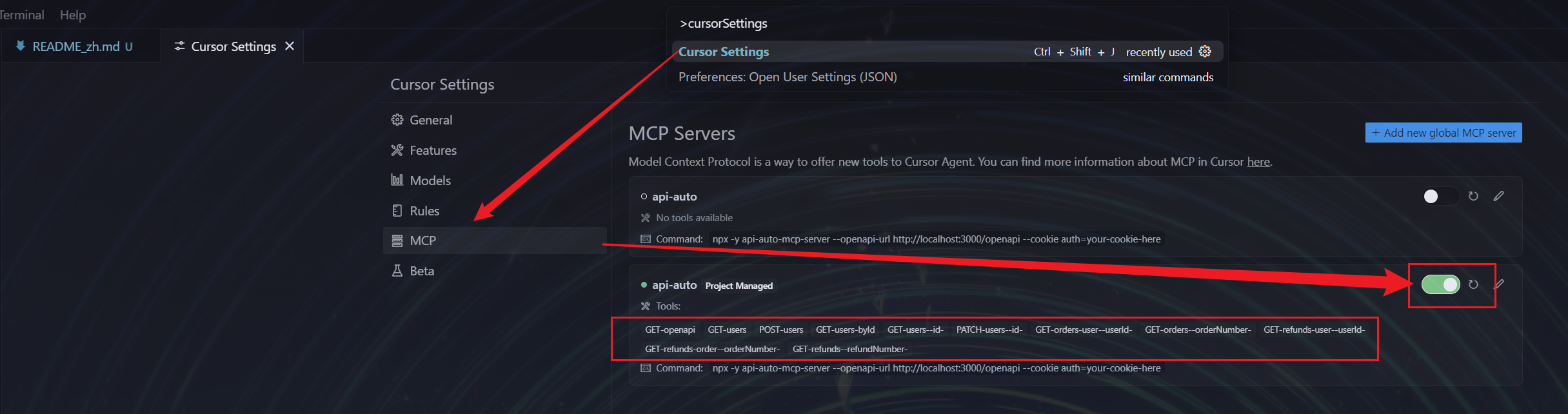
VScode
如果是使用VScode打开该项目,操作步骤如下:
- 打开Github Copilot的聊天窗口;
- 点击刷新按钮,此时会出现提示
Trust MCP Server from api-auto-mcp-server-demo/.cursor/mcp.json?; - 点击
Trust进行确认。
确认后,刷新按钮会变为扳手按钮,并显示相应数字,这表示 MCP 服务器已成功启动。 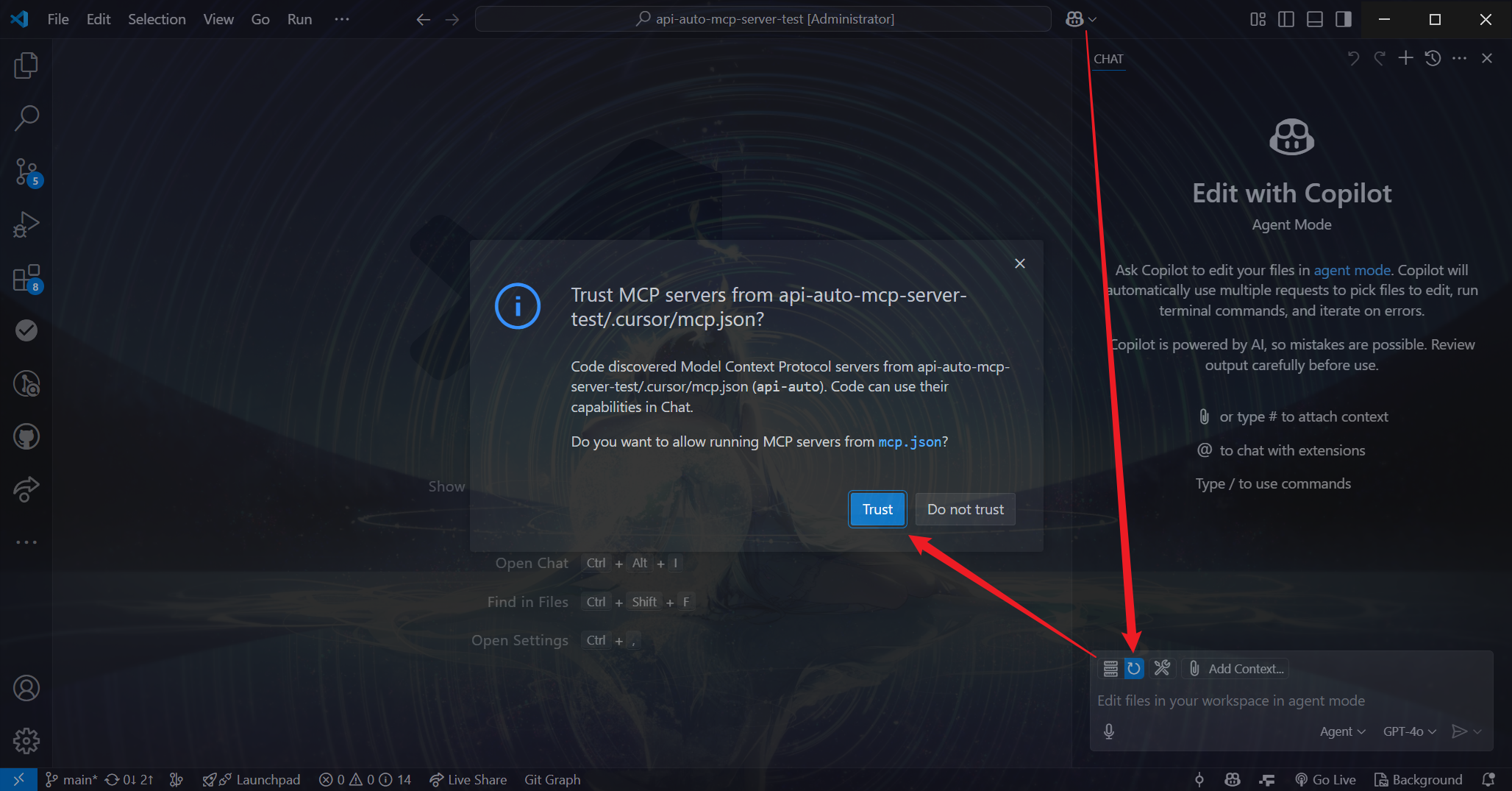 完成上述所有操作后,就可以像演示效果中那样,向 AI 提出问题,让其自动调取接口获取信息并汇总呈现。
完成上述所有操作后,就可以像演示效果中那样,向 AI 提出问题,让其自动调取接口获取信息并汇总呈现。
服务接入:将工具融入你的系统
若要将 API Auto MCP Server 应用到自己的后端服务中,需要完成以下关键步骤:
接口准备:后端服务需提供一个 get 接口,该接口用于返回服务的 OpenAPI 规范的 json 文件 。OpenAPI 规范是一种用于描述 RESTful API 的标准,它详细定义了接口的路径、请求方法、参数、响应等信息。
配置修改:将示例项目中的 .cursor/mcp.json 文件里的 http://localhost:3000/openapi ,替换为你自己服务的 OpenAPI 规范的 json 文件的地址 ;
参数配置(可选):如果后端服务需要传递 cookie 等信息进行身份验证或其他操作,可以在 .cursor/mcp.json 文件中,将 auth=your-cookie-here 修改为实际需要的配置 。配置示例如下:
{
"mcpServers": {
"api-auto": {
"command": "npx",
"args": [
"-y",
"api-auto-mcp-server",
"--openapi-url",
"http://your-openapi-json-url",
"--cookie",
"auth=your-cookie-here"
]
}
}
}完成配置修改后,等待 MCP 服务器重启,此时服务器会根据后端服务接口,自动注册相应的工具 。
注册完成后,就可以围绕后端服务的业务逻辑,向 AI 提问和获取回答了。
深度解析:背后的运行原理
通过前面的示例效果和操作步骤,我们已经对 API Auto MCP Server 有了初步认识。接下来,深入剖析其运行原理,了解 AI 是如何通过 MCP 实现与后端服务的无缝对话。
从整体流程来看,AI 主要借助 MCP 提供的工具(tool)来调用后端接口获取信息,具体流程如下: 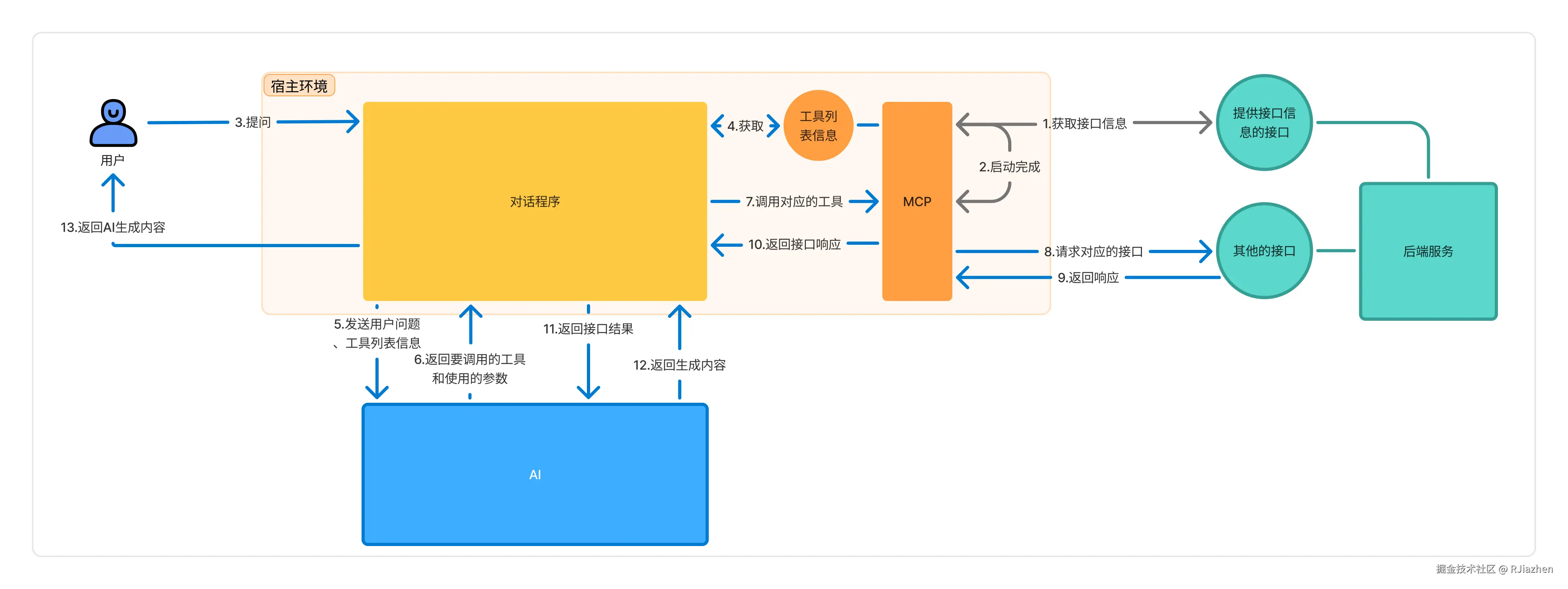
AI 利用 API Auto MCP Server 调用后端接口服务回答问题
在整个流程中,步骤 1 - 2 在宿主环境(如 VScode 或 Cursor )启动时自动完成,从步骤 3 用户提问开始,正式触发 MCP 工具的调用。
与常规 AI 聊天不同的是,该流程多出了步骤 6 到 11 。AI 在接收到问题后,不会立即给出回答,而是先判断是否需要调用 MCP 工具 。若需要调用,AI 会先执行工具调用操作,获取数据后,再基于这些数据生成最终回答。
在单次对话中,步骤 6 到 12 一般只执行一次,但由于多数具备 MCP 功能的 AI 工具以 Agent 形式运行,会根据 AI 的判断,多次重复执行这一系列步骤,以实现复杂任务的处理。
这一流程的实现,核心依赖两个关键步骤:
MCP 构建交互桥梁:作为 AI 与后端服务联通的桥梁,需要通过 MCP 进行接口的请求和响应;
自动创建 MCP 服务器:根据后端服务特性,自动生成适配的 MCP 服务器,实现工具的动态注册与调用 。
下面,我们对这两个核心步骤进行详细解读。
MCP:AI 与外界交互的底层协议
MCP,即 Model Context Protocol(模型上下文协议),它并非具体的技术实现或代码实践,而是一种用于规范 AI 与其他系统交互的标准 。在当前 AI 生态中,MCP 已成为实现 AI 与外部系统交互的底层通用标准,其完善的生态配套,已经是各类 AI 应用开发的不二选择。
API Auto MCP Server 正是基于 MCP 标准开发的 MCP 服务器,前文提到的 MCP 配置环节,本质上就是对该服务器启动命令的设置。那么,AI 是如何知晓有哪些 MCP 工具可供调用,又该如何进行调用呢?
为解答这一问题,我使用 Fiddler 对 Github Copilot 进行抓包分析,并将相关数据存储在代码仓库中 。以一次查询汇总用户信息的对话为例,其交互流程包含三次请求与响应: 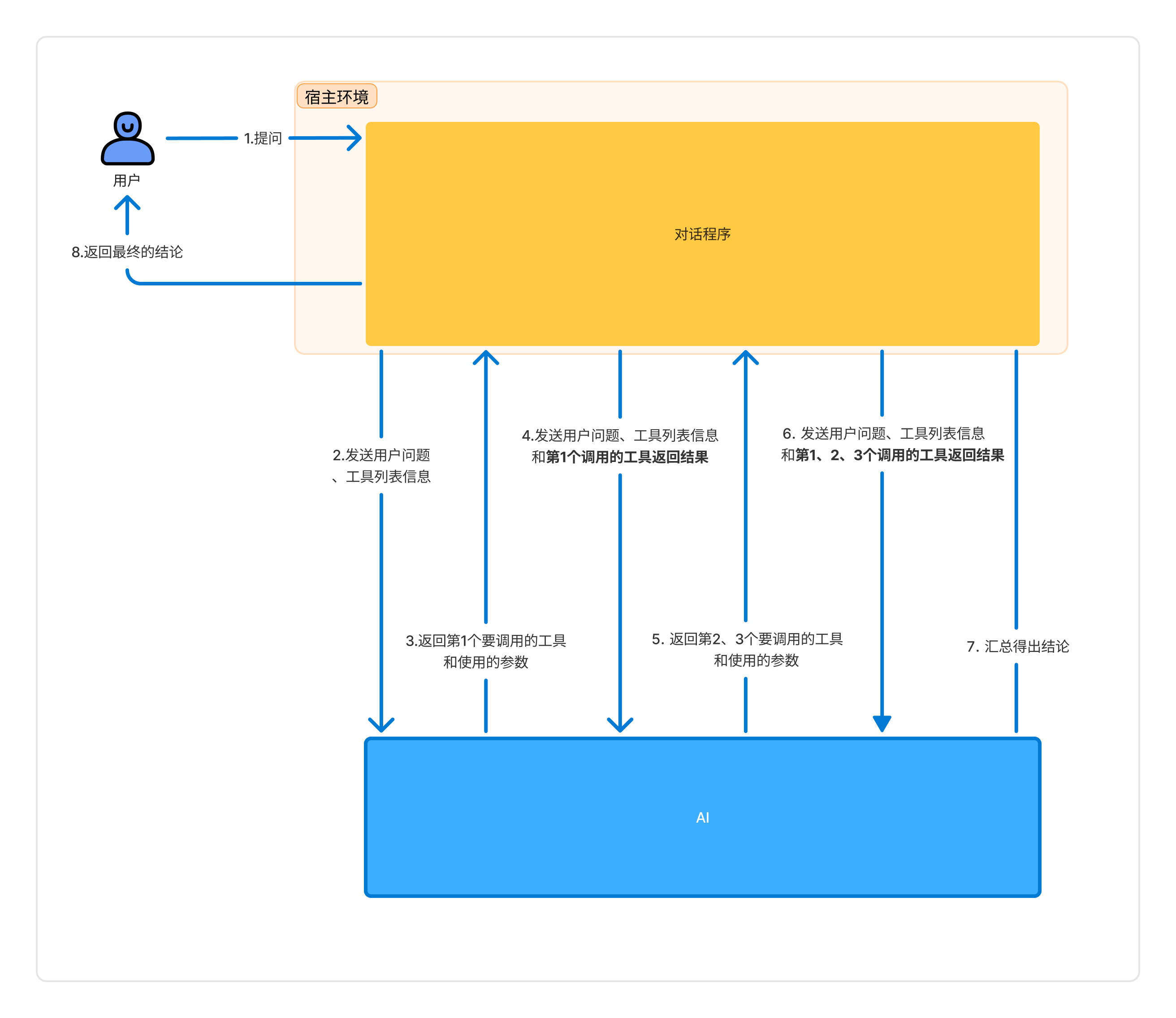
Github Copilot 使用 MCP 回答问题过程
- 第一次请求:携带用户提问内容以及 MCP 相关信息;
- 第一次响应:返回本次需调用的第 1 个 MCP 工具(用于获取用户基本信息)的具体内容;
- 第二次请求:包含用户提问、MCP 相关信息,以及第 1 个 MCP 工具的调用结果;
- 第二次响应:给出接下来要调用的第 2、3 个 MCP 工具(分别用于获取用户订单信息和退款记录信息)的详细内容;
- 第三次请求:整合用户提问、MCP 相关信息,以及前 3 个 MCP 工具的调用结果;
- 第三次响应:AI 基于所有工具调用结果,汇总整理并返回最终答案 。
进一步分析请求内容可知,所有 MCP 工具信息存储在 tools 数组中,而之前工具的调用结果则保存在 message 中。以第二次请求内容为例:
// 第二次请求时发送的内容
{
"messages": [
// ... 发送的信息
// 经过修饰后的用户提问
{
"role": "user",
"content": "<context>\nThe current date is April 28, 2025.\nMy current OS is: Windows\nI am working in a workspace with the following folders:\n- d:\\New folder \nI am working in a workspace that has the following structure:\n```\n\n```\nThis view of the workspace structure may be truncated. You can use tools to collect more context if needed.\n</context>\n\n<reminder>\nWhen using the insert_edit_into_file tool, avoid repeating existing code, instead use a line comment with `...existing code...` to represent regions of unchanged code.\n</reminder>\n<prompt>\n查询id为1的用户的相关信息,包括订单记录、退款记录等,并总结该用户特点\n</prompt>"
},
// 之前调用的MCP工具的信息
{
"role": "assistant",
"content": "",
"tool_calls": [
{
"function": {
"name": "331_GET-users-byId",
"arguments": "{\"id\":1}"
},
"id": "call_J0Qpk5HjZMVkvtaf8XO65tGI",
"type": "function"
}
]
},
// 之前调用的MCP的结果
{
"role": "tool",
"content": "{\n \"id\": 1,\n \"name\": \"John Doe\",\n \"email\": \"john@example.com\",\n \"age\": 30,\n \"role\": \"admin\"\n}",
"tool_call_id": "call_J0Qpk5HjZMVkvtaf8XO65tGI"
},
// 对于上述信息的描述
{
"role": "user",
"content": "Above is the result of calling one or more tools. The user cannot see the results, so you should explain them to the user if referencing them in your answer. Continue from where you left off if needed without repeating yourself."
}
],
"tools":[
// ...其他的工具
// 一个用来创建用户的MCP工具的描述信息
{
"function": {
"name": "331_POST-users",
"description": "Create a new user",
"parameters": {
"type": "object",
"properties": {
"requestBody-id": {
"type": "number"
},
"requestBody-name": {
"type": "string"
},
"requestBody-email": {
"type": "string"
},
"requestBody-age": {
"type": "number"
},
"requestBody-role": {
"type": "string"
}
},
"additionalProperties": false,
"$schema": "http://json-schema.org/draft-07/schema#"
}
},
"type": "function"
},
]
}基于上述原理,我们可以使用普通对话 AI 模拟该交互流程:
打开 DeepSeek(经测试,其他对话 AI 在此场景下效果欠佳),注意关闭 R1 和联网搜索选项; 复制第一次请求的内容 ,发送给 DeepSeek; DeepSeek 会返回包含 MCP 工具列表的 json 数据,大概率会调用 331_GET-orders-user--userId- 方法,并传递 userId 为 1 的参数; 复制第二次请求的内容 ,再次发送给 DeepSeek; DeepSeek 返回包含后续待调用 MCP 工具的 json 数据,由于 DeepSeek 未针对此场景进行深度优化,可能仍仅请求一个工具; 假设 DeepSeek 一次性调用两个 MCP 工具,直接复制包含这两个工具调用结果的第三次请求的内容 ,发送给 DeepSeek; 此时,DeepSeek 不再请求 MCP 工具,而是基于获取的数据,返回汇总分析结果 。
- 打开 DeepSeek(经测试,其他对话 AI 在此场景下效果欠佳),注意关闭 R1 和联网搜索选项;
- 复制第一次请求的内容,发送给DeepSeek;
- DeepSeek大概率会返回一个包含MCP工具的列表的json数据,且大概率会调用
331_GET-orders-user--userId-这个方法,并传递userId为1的参数; - 复制第二次请求的内容,发送给DeepSeek;
- DeepSeek 返回包含后续待调用 MCP 工具的 json 数据,由于 DeepSeek 未针对此场景进行深度优化,可能仍仅请求一个工具;
- 假设 DeepSeek 一次性调用两个 MCP 工具,直接复制包含这两个工具调用结果的第三次请求的内容,发送给 DeepSeek ;
- 此时,DeepSeek 不再请求 MCP 工具,而是基于获取的数据,返回汇总分析结果 。
由此可见,MCP 的核心机制是将工具信息转换为提示词传递给 AI,AI 依据提示返回工具调用指令,系统解析指令后调用工具,并将工具返回值再次作为提示词反馈给 AI,从而实现 AI 和外部系统的无缝对话。
MCP 服务器与后端服务的适配
在理解 MCP 与 AI 的交互原理后,我们再来探究 MCP 服务器如何根据后端服务自动生成可用工具并实现调用。
最直接的实现方式是手动编写各接口的参数解析与调用逻辑,然而,实际的后端服务往往包含成百上千个接口,且随着业务发展不断新增,手动编写所有逻辑显然不切实际。
如同 MCP 协议帮助 AI 与外部工具对接一样,MCP 与后端接口的对接也依赖一个通用规范 —— OpenAPI。OpenAPI 规定了接口描述自身信息的标准,各类后端框架和接口管理工具能够便捷生成符合该标准的接口描述信息。
前文示例项目的接口文档,便是基于 OpenAPI 标准自动生成的:
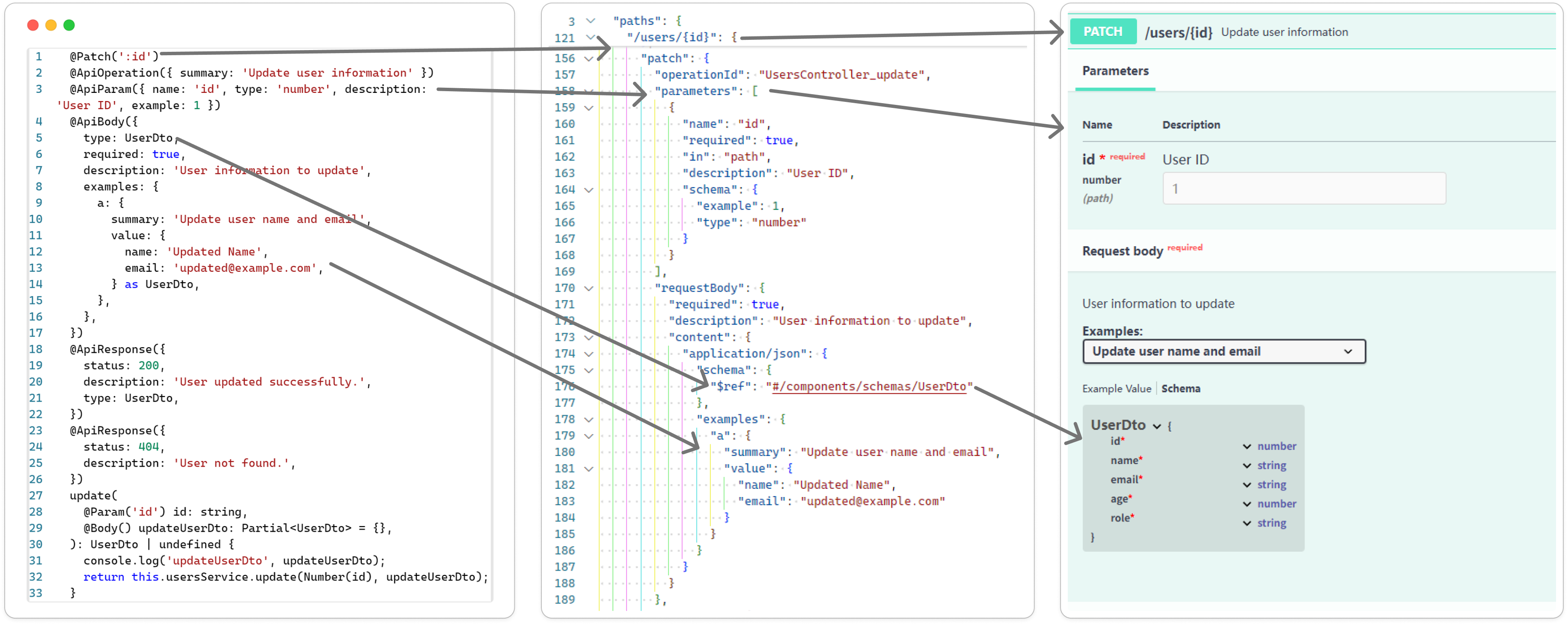
Swagger插件通过生成的OpenAPI标准的数据生成接口文档
和生成接口文档类似,也可以编写程序自动生成 MCP 的各种工具。
以下是使用符合 OpenAPI 标准的接口信息自动注册 MCP 工具的大致实现代码,通过这段 TypeScript 代码,我们能更清晰地看到其底层逻辑:
/**
* 使用符合OpenAPI标准的接口信息自动注册MCP工具 的大致实现
*/
export const registerTools = async (
server: McpServer,
openApiDoc: OpenAPIV3.Document,
) => {
// 遍历接口信息
for (const [path, pathItem] of Object.entries(openApiDoc.paths)) {
for (const [method, operation] of Object.entries(pathItem)) {
// 解析获得请求地址
const cleanPath = path.replace(/^\//, '');
// 根据请求方法、请求地址生成工具ID
const toolId = `${method.toUpperCase()}-${cleanPath}`.replace(
/[^a-zA-Z0-9-]/g,
'-',
);
// 解析生成工具的描述信息
const description =
operation.summary ||
operation.description ||
`${method.toUpperCase()} ${path}`;
// 解析获得param信息
const validParameters =
operation?.parameters?.filter(
(param) => 'name' in param && 'in' in param,
) || [];
// 解析获得param的schema
const validParametersSchema = (()=>{
// ...
})()
// 解析获得requestBody中的参数
const requestBody = (() => {
if (!operation.requestBody) {
return undefined;
}
// ...
return schema;
})();
// 解析获得requestBody中参数的schema
const requestBodyInputSchema = (() => {
if (!requestBody) {
return undefined;
}
// ...
})();
// 汇总为总的schema
const inputSchema: Record<string, z.ZodType> = {
...validParametersSchema,
...requestBodyInputSchema,
};
// 使用生成的schema注册该接口对应的工具
server.tool(toolId, description, inputSchema, async (params) => {
// ...
});
}
}
};这段代码首先遍历 OpenAPI 文档中的每个接口路径和请求方法,为每个接口生成唯一的工具 ID 和描述信息。
接着,分别解析路径参数和请求体参数的 schema,将其合并为工具的输入参数 schema。
最后,使用生成的 schema 在 MCP 服务器上注册工具,并定义工具的调用逻辑,即根据传入的参数调用实际的后端接口,并返回接口响应结果。
写在最后——关于MCP和AI的未来
经过这两年各种 AI 模型和工具的快速发展,可以说 AI 全面接入数字世界只差临门一脚了,而 MCP 就是迈向这最后一步的钥匙。从 MCP 提出到现在的几个月时间,无论是各种社区项目的诞生,还是各大厂商的积极跟进,都证明了只要各种 “共识” 能够确立,整个 AI 生态的活力也会被逐步释放。
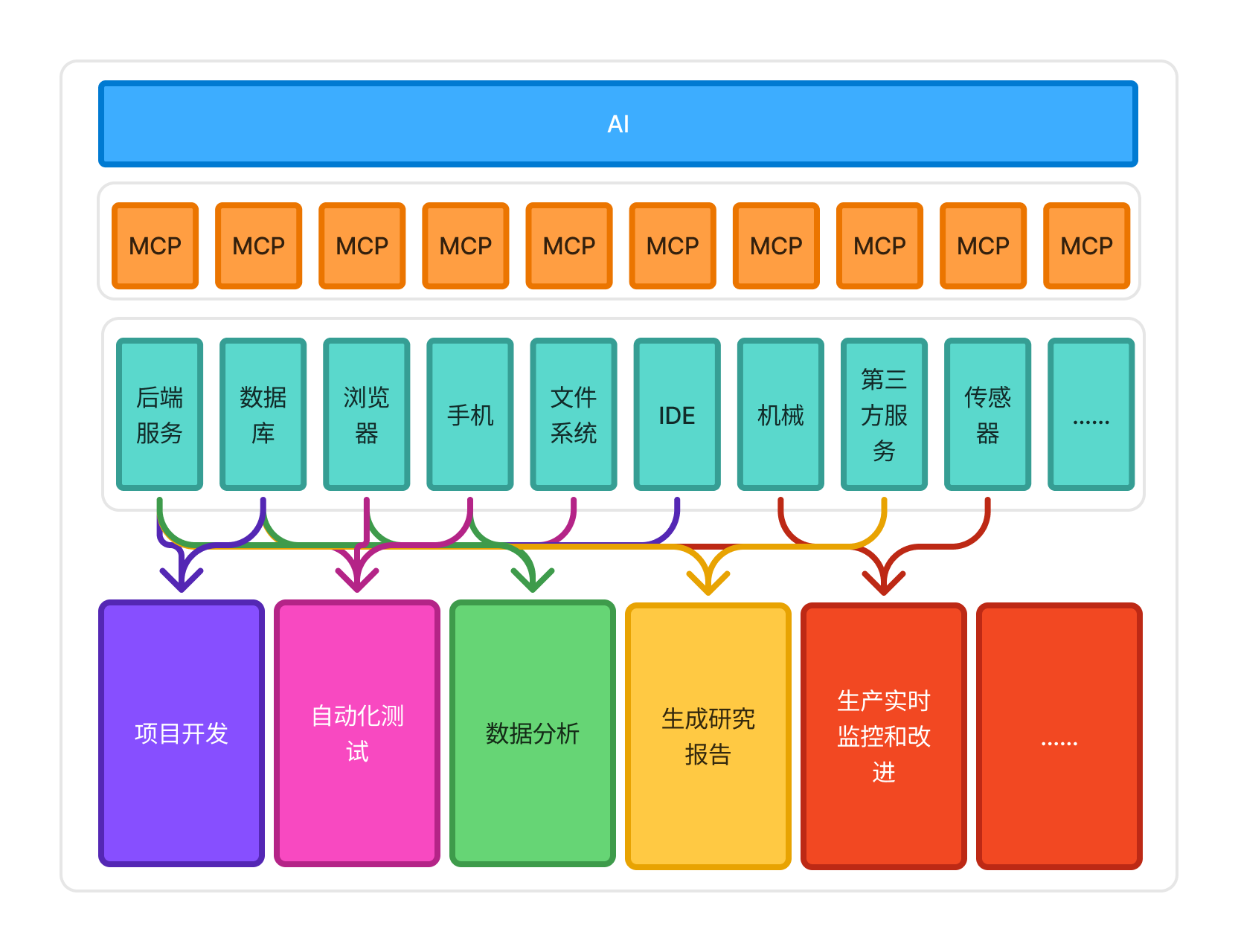
AI 通过 MCP 对接整个数字世界
未来,随着 MCP 协议的不断完善和普及,AI 与后端服务的集成将更加紧密和智能。想象一下,在企业级应用中,AI 客服能够自动调用企业内部的各种业务接口,快速准确地回答客户问题、处理订单;在数据分析领域,AI 可以自动连接不同的数据接口,整合多源数据进行深度分析,为企业决策提供更有力的支持。
此外,MCP 还有望推动跨平台、跨系统的 AI 应用开发。不同企业、不同系统之间可以基于 MCP 协议实现 AI 能力的共享与协作,打破数据和功能的壁垒,构建更加开放、高效的 AI 生态系统。 我们有理由相信,在 MCP 的助力下,AI 将真正融入我们生活和工作的方方面面,开启一个全新的智能化时代。
如果你在使用 API Auto MCP Server 过程中遇到任何问题,或者有新的想法和需求,欢迎随时交流分享,一起探索 AI 与后端服务集成的更多可能!